COMPASS
An Intelligent Dictionary System
for Reading Text in a Foreign Language
Electronic dictionaries have substantially simplified the
time-consuming task of looking up words. This is particularly true
when the text to be read is in electronic form, a reading situation
that is becoming more and more significant with the increasing spread
of computer networks and electronic books and documents.
However, at present neither electronic dictionaries themselves, nor
the look-up techniques, are well suited to what is possible within an
electronic medium. Dictionaries offer an electronic image of
reference works in a print medium designed for human manipulation.
Look-up techniques are restricted generally to comparing strings of
characters in the text with the strings that occur as dictionary
headwords: when the strings match, the corresponding entry is
displayed. These systems do not take account of the intellectual
abilities of the human dictionary user. Furthermore, they leave it up
to the user to relate inflected forms to their base, to identify part
of speech, and to pick out the appropriate sense somewhere in an
extended dictionary entry.
The COMPASS project seeks to demonstrate that these restrictions on
conventional electronic dictionaries can be overcome by the
application of existing techniques. To this end a prototype of a
computer programme is being developed, which accesses enhanced and
structurally elaborated dictionaries with an intelligent,
context-sensitive look-up procedure, presenting the information to the
user through an attractive graphical interface.
The prototype's performance is being evaluated through a series of
user tests. These have given rise to some quite ringing endorsements
of the system by the test users. For example, in response to a
question on whether COMPASS is more efficient than a paper dictionary,
users have commented:
- "I get fed-up with leafing through paper dictionaries. I
prefer being able to scan ahead like this." (L1C15)
- "Chief advantage is the speed, and that the user can go on
working on the text whilst Compass is accessing the translation
options." (L1C19)
- "More efficient particularly for a weak language
competence." (L1C02)
The results show that reading foreign-language texts is substantially
easier with a system such as COMPASS, and a better understanding of
the text can be gained. In fact we believe that in many cases where
the reader already has a basic knowledge of the foreign language use
of such a system can obviate the need for translation.
The sections below offer more detail on the components of the
prototype and organization of the COMPASS project.
The Dictionaries
The lexicographic basis for the project is supplied by the Collins
German Dictionary (German-English) [published by HarperCollins and
Klett, Verlag fźr Wissen und Bildung] and the Oxford-Hachette
Dictionary (English-French). Machine-readable versions of these
dictionaries were licensed to the partners in the project for research
purposes. With these two dictionaries the prototype is able to cover
the English-French and German-English language pairs. By the terms of
the licence, and in order to make effective use of limited staff time,
only excerpts from these dictionaries were used for the prototype.
Technical Adaptation of the Dictionaries
The machine-readable versions of the dictionaries provided by the
publishers were SGML-marked type-setting tapes. In order to enable
selective access to the information in the dictionary entries, the
entries need to undergo a thorough structural analysis. For this the
dictionary parser Lexparse was used, which can recognize, and
explicitly represent, the hierarchical micro-structure of dictionary
entries using a grammar defined by the user. The Lexparse grammars
developed for the two dictionaries cover as comprehensively as
possible all the structures of the dictionary entries, excluding
inconsistent and faulty entries: these make up a considerable part of
the dictionary. The faulty entries are corrected manually and parsed
a second time. The resulting SGML-annotated dictionaries together
with the DTD (document type definition) generated by Lexparse could
then be lexicographically adapted in an SGML editor.
Partly during the parsing, partly during the subsequent processing, some unpacking of, and corrections to, the mark-up were introduced. To create the index it was necessary to spell out lemma-variants and expand sub-entries. For the most part these tasks were performed automatically. Finally the two resulting "lexical databases" derived from each dictionary were converted into a common data structure used by the LOCOLEX look-up system.
Extensions to the Dictionaries
To make true "comprehension dictionaries" from the parsed
dictionaries, various lexicographical adjustments were necessary. All
information in an entry that is unnecessary for the understanding of
the word has to be marked explicitly for suppression in the COMPASS
system. For example:
- Explicit marking of alternative, almost synonymous translations;
e.g.. the complex translation equivalent 'to switch {or} turn {or} put
on' for 'einschalten' is transformed into three simple translations
and marked up as such allowing COMPASS to hide the second and third
translation variants.
- Using various markings to distinguish usage examples, which are
only important for language production, from semantically complex
multi-word lexemes, which can only be understood only as a whole.
(Only the latter should appear in a comprehension dictionary.)
- Separate marking of prepositional complements when they appear
within the translation equivalent.
Within a group of synonyms the most general translation should be
given first, so that COMPASS can select this as a reduced
representation of the entry. Further unpacking was sometimes
necessary, e.g. to supply explicit translations where for reasons of
space only implicit example phrases are given. Of course we also
needed to supply missing variant forms, missing senses, completely
absent headwords and multi-word expressions (MWE), the latter
discovered from corpus excepts and the automatic extractions of
possible MWE from textual corpora.
Formalization of Context Patterns
The COMPASS system should recognize whether a word queried occurs in a
definite context where a special translation is appropriate, and in
that case select it. To make this possible, corresponding context
patterns must be supplied the in COMPASS dictionary. For this purpose
Rank Xerox uses a finite state formalism in which such context
patterns are coded as regular expressions. The context formalization
is restricted initially to the recognition of multi-word expressions
and grammatical collocations.
The formalization is achieved through a number of steps. First the
decision is made which contexts overall should be formalized. MWE and
grammatical collocations are then reduced to a so-called "canonical"
form, which also includes lexical variants. Morphologically variable
elements are marked as such. On the basis of these canonical forms a
regular expression is generated, which encompasses, e.g., the
variations in word-order that German allows. Special ways in which
particular MWE may allow variation are added by hand to the regular
expressions.
The LOCOLEX Look-up System
The basis of the look-up system is the LOCOLEX system, developed and
patented by Rank Xerox. The kernel of LOCOLEX performs the actual
look-up and loads the relevant parts of a dictionary entry on the
basis of a linguistic analysis of the word's environment. To speed
access to individual dictionary entries it uses an index of headwords
and their variants. The LOCOLEX software is largely
system-independent. It can be developed on, and ported onto, a
variety of computer architectures.
The components for linguistic analysis of the source language (the so-called "language model") are not a direct part of the LOCOLEX kernel. Language models are developed separately for languages as required and attached to the LOCOLEX kernel as finite automata. Among the most important components of a language model are algorithms for morphological analysis and identification of parts of speech. Over and above these, the language model includes definitions of the macros and variables for finite automata which are used to recognize multi-word expressions.
Morphological Analysis
The morphological analysis reduces inflected words to their base-form and thus allows inflected words to access their dictionary entries (e.g. of gesungen to the headword singen). It also provides morphosyntactic information (part of speech, case, number and gender) which is used in subsequent steps of the analysis to select the correct meaning.
Part of Speech Disambiguation
If morphological analysis results in ambiguous syntactic information (e.g. article or verb for einen in German, noun or verb for plan in English) this ambiguity is resolved by a Part of Speech Disambiguation component. This uses a probabilistic procedure known as a Hidden Markov Model. These components are especially important for English or French, where many content words are ambiguous as to their part of speech.
Loading the Relevant Parts of a Dictionary Entry
The output of morphological analysis and part of speech disambiguation
is used to select the parts of a dictionary entry relevant to a given
context. The complete dictionary entry is loaded into main memory via
an index. This procedure converts the given SGML structure of the
dictionary entry into a largely dictionary-independent system-internal
data-structure, and the part selected by the disambiguation is
specially marked.
Recognition of Multi-World Expressions
If the selected word is part of a multi-word expression and coded as
such in the dictionary entry, the system returns the translation of
the whole MWE. This is a further step towards selecting the
information relevant to the context from the dictionary entry. For
this the MWE coded as regular expressions in the selected dictionary
entry is compared with the input text. If a regular expression
matches the sentence context, the translation of the corresponding MWE
is marked specially and displayed first to the user as an answer to
his query.
Graphical User Interface
For the representation of texts and dictionary entries a special
graphical user interface has been developed for Apple Macintosh
computers. The kernel of this user interface is a so-called "reader",
a simple editor program that permits the display of texts, and
annotation of individual words with translations, but also changes to
the text itself. Accordingly, this reader offers three modes: read,
assist and edit.
For application as a reading aid the assist mode is of particular
interest. In this mode a look-up and analysis process can be
activated by simple selection of a word with the mouse. Reacting to a
mouse-click, a small help window appears, placed close to the selected
word so as to cover as little as possible of the context. The window
displays a list of the translations that appear relevant in the light
of the analysis of the context:
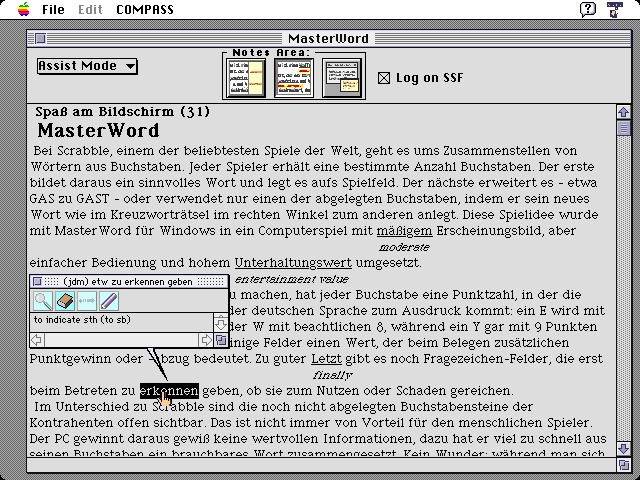
The user is offered various options in the help window:
- If the user selects an individual gloss, the word appears in the text annotated with this gloss. There are three options as to where to place this annotation, which can be pre-set by the user:
- interlinear gloss: the additional text appears between the lines
beneath the glossed word
- marginal gloss: the text appears in the margin at the level of the
line containing the word
- gloss in separate window: the glosses are written sequentially in
a separate window.
- If the user desires further information on an individual sense it
can be displayed by clicking on the button attached to the desired
sense.
- Finally, the whole dictionary entry can be displayed through
clicking on a special button for this purpose..
- If the user makes no selection, the help window remains visible
for a pre-set time before disappearing.
Session Storage
In addition to the representation of the relevant lexical information
on the screen some data is recorded in a storage file. The nature and
scope of this data can be set by the user. This function, for
examples, makes it possible later to review the unknown vocabulary in
a text.
User Tests
The first evaluation of the prototype was conducted in the summer of
1995 in user tests at the Universities of Bournemouth (for
German-English) and Lyon 2 (for English-French). For each of the two
source languages German and English there were two designated
newspaper articles, read with the help of the COMPASS system by test
users with a basic knowledge of the language. The test users' reading
comprehension was examined at the end by comprehension questions. In
addition the test users were asked to complete a questionnaire to
assess the various COMPASS functions.
The results have been overwhelmingly positive, even at the first test
phase. A second test phase will be conducted with an improved version
of the prototype at the beginning of 1996.
Project Data
The official title of the project is:
COMPASS: Adapting bilingual dictionaries for on-line COMPrehension ASSistance. The project is supported within the framework of the Linguistic Research and Engineering as no. 62-080 by DG-XIII of the European Commission from April 1994 to March 1996. The project partners are:
- Rank Xerox Research Centre, Grenoble (Co-ordinator)
- Fraunhofer Institut für Arbeit und Organisation, Stuttgart
- Seminar fźr Sprachwissenschaft, Universität Tübingen
- Language Unit, Bournemouth University
- Langues Étrangères Appliquées, Universté Lyon 2
Helmut Feldweg